


At MPP Insights, we build BI platforms where companies can analyze their data and create dashboards. A big part of our work is adding AI models that can understand data, read database structures, and help users work faster.
The problem is, most strong AI models need multiple GPUs to run well. That makes things expensive and harder to manage, especially for companies that want to run everything on their own setup.
This is even more important in BI systems. These workflows usually include large schemas, documentation, and long interactions. So the model needs to handle a lot of information, while still being fast enough to feel responsive.
When NVIDIA released Nemotron 3 Super on March 11, 2026, our technical team decided to test it. It is a 120B model, but because of how it is designed, only about 12B is active per request. They also released a version that can run on a single 96GB GPU.
This is what caught our attention; if a model this big can run on one GPU, it makes testing and deployment much easier. In this article, we compare nvidia nemotron 3 super vs gpt oss 120b in real BI use cases.
So our technical team loaded it on a single RTX PRO 6000 and tested it inside MPP BI, our business intelligence platform for data analytics and visualization. MPP BI is built on a data-centric architecture, which means instead of copying data out to a separate engine for processing, it runs computations directly inside the database where the data already lives.
In this article, we share what we learned from that testing inside our BI system.
Quick answer: On SWE-Bench Verified, Nemotron 3 Super scores 60.5 versus 41.9 for GPT-OSS-120B. GPT-OSS runs about 2x faster, while Nemotron holds long context better up to 256K tokens.
Why Nemotron 3 Super Caught Our Attention
Nemotron 3 Super can run on a single GPU, models in this size range usually require several GPUs to serve reliably.
For us, that was exactly what we wanted to explore. If a model at this scale can realistically run on one GPU, it becomes much easier to test new ideas, run experiments on real data, and evaluate how it performs inside our BI workflows.
Because of these characteristics, we decided to run a full evaluation of Nemotron 3 Super inside the MPP BI platform. Before we jump into our experiment, it’s worth looking into the exact features of Nemotron 3 Super.
Mixture-of-Experts architecture
NVIDIA designed the model as a Mixture-of-Experts (MoE) system. The total model size is 120 billion parameters, but only about 12 billion parameters are active during each request.
Inside the model there are many expert blocks (small specialized parts of the model trained to handle specific types of tasks). When a request arrives, the model does not activate all of them. Instead, a small component called a router selects the experts that should handle the task.
In other words, the model has many specialized parts, but it only uses the ones that are needed for the current query. This allows the model to stay large and capable while reducing the amount of computation required for each request.
Hybrid Mamba–MoE architecture
Mamba is a newer sequence-processing approach that helps models work with long text inputs more efficiently. This helps Nemotron process large amounts of context without losing track of earlier information.
For example, the model can handle:
- very large documents;
- long conversations;
- complex database schemas.
This is especially useful for analytical work where the model has to handle a lot of structured data.
Open weights and training transparency
NVIDIA also released the model with open weights, open training data, and an open training recipe. For teams working with AI infrastructure, this level of transparency is useful. Researchers and companies can study how the model was trained and reproduce the process if needed.
NVFP4 precision format
Many models are trained at high precision and then compressed later to reduce memory usage. This compression often leads to some loss in accuracy.
Nemotron 3 Super was trained directly in NVFP4 from the start, which means it uses a very compact 4-bit format, so it needs much less memory without losing much accuracy. Because of this, it avoids most of the accuracy drop that usually comes from compression, while still using much less memory.
This is what allows the model checkpoint to fit on a single 96GB GPU, while still leaving enough space for the KV cache when the model is running and generating answers.
Comparison setup
To keep the comparison fair, we focused on models that run in a similar setup.
The main comparison is GPT-OSS-120B. Both models can run on a single high-end GPU, so they are realistic for production, including MPP BI deployments.
We also included Qwen3.5-122B as a reference. It performs well, but it usually needs 4–8 GPUs, so it is less practical for our setup.
Our goal was to test these models in real conditions inside MPP BI.
We focused on three things:
- Can the model run on a single high-end GPU?
- Does it stay stable with a long context?
- Does it work across different languages we see in practice?
Even before running our own tests, some differences were already clear.
Qwen3.5-122B needs 4–8 GPUs to handle large contexts, so it doesn’t fit our deployment setup.
GPT-OSS-120B can run on one GPU, but in our experience its quality drops after around 128K tokens.
Nemotron 3 Super runs on a single 96GB GPU and stays stable between 64K and 256K tokens. This is the range where GPT-OSS becomes less reliable in real BI scenarios, where context can grow quickly.
That is why we decided to test Nemotron more closely.
What the Benchmarks Say
Before testing the model inside MPP BI, we first looked at public benchmarks. We wanted to understand where Nemotron 3 Super stands compared to other models before spending time on real workloads.
These numbers come from public evaluations used across the AI community to compare models on different tasks.There was a lot of information here, so we focused only on what matters for our use case.

1- Long Context Performance
The first thing we checked was long context performance. Long context means how much text a model can handle at once. This includes long conversations, large documents, or complex database schemas. In BI systems like MPP BI, this matters because the model often works with large and growing context.
For this, we looked at a benchmark called RULER which is a test that checks how well a model can understand and reason over very long inputs.For this, we looked at a benchmark called RULER which is a test that checks how well a model can understand and reason over very long inputs.
At 256K tokens, Nemotron scores 96.3%, while GPT-OSS scores 52.3%.
At 512K tokens, Nemotron stays at 95.7%, while GPT-OSS drops to 46.7%.
At 1M tokens, GPT-OSS drops sharply to 22.3%, while Nemotron still stays around 91.8%.
Result
Nemotron stays stable even when the input gets very large. GPT-OSS starts to lose track as the context gets longer.
What This Means for BI Systems
This matters a lot for BI workloads. Analytical systems often deal with large database schemas, long queries, and multiple documents at the same time. In BI systems, this context can quickly grow to hundreds of thousands of tokens.
As context grows, many models start to fail. They miss details, forget earlier instructions, and become less accurate. Nemotron 3 Super keeps stable performance much longer.

If you are already working with BI tools and thinking about upgrading your setup, it is also worth exploring modern ibm cognos alternatives like MPP BI, especially if you need more flexibility and built-in AI capabilities.
2- Coding and Reasoning Benchmarks
On SWE-Bench Verified, which tests real software engineering tasks, Nemotron performs better with 60.5 compared to 41.9.
On LiveCodeBench, which tests code generation and correctness, GPT-OSS leads with 88.0 compared to 81.2.
On math benchmarks like AIME, GPT-OSS also has a small edge with 92.5 compared to 90.2.
Result
So at this stage, there was no clear winner. Each model was strong in different areas.
What We Tested Ourselves: Languages Beyond English
MPP BI is used in multilingual environments, and our R&D office is in Yerevan, Armenia. We also work with clients and data in multiple languages, so we wanted to understand how these models behave when English is not the main language.
We ran our own tests on Nemotron and GPT-OSS-120B using the same hardware, the same software stack, and the same evaluation process, and we focused on Armenian and Georgian because these are low-resource languages where training data is limited, which makes them a good stress test for multilingual ability.
INCLUDE: Real exam questions in Armenian and Georgian
INCLUDE is a benchmark made of real exam questions written directly in Armenian and Georgian, not translated from English, and this difference matters because translated benchmarks usually follow English patterns and are easier for models to handle, while native questions are more natural and harder.
On both Armenian and Georgian, both models perform at a relatively low level and stay close to each other, with Nemotron showing a small advantage but not a meaningful gap. This tells us that both models still have clear limitations when it comes to low-resource languages, and neither of them is strong enough here to be relied on in isolation.
What do these scores tell us
These scores may look low, and they are. But that does not mean these models are bad overall. Both models have improved significantly in other areas like handling long context and coding. The models are getting better as a whole, it is just that non-English language support for lower-resource languages like Armenian and Georgian has not caught up yet.
The purpose of this test was not to measure how close these models are to perfect. It was to compare how they perform against each other in the same conditions.
ArmBench: Armenian reasoning across subjects
ArmBench contains 1,000 Armenian questions where the model needs to reason step by step before producing a final answer, which makes it a better test of reasoning quality rather than simple recall.
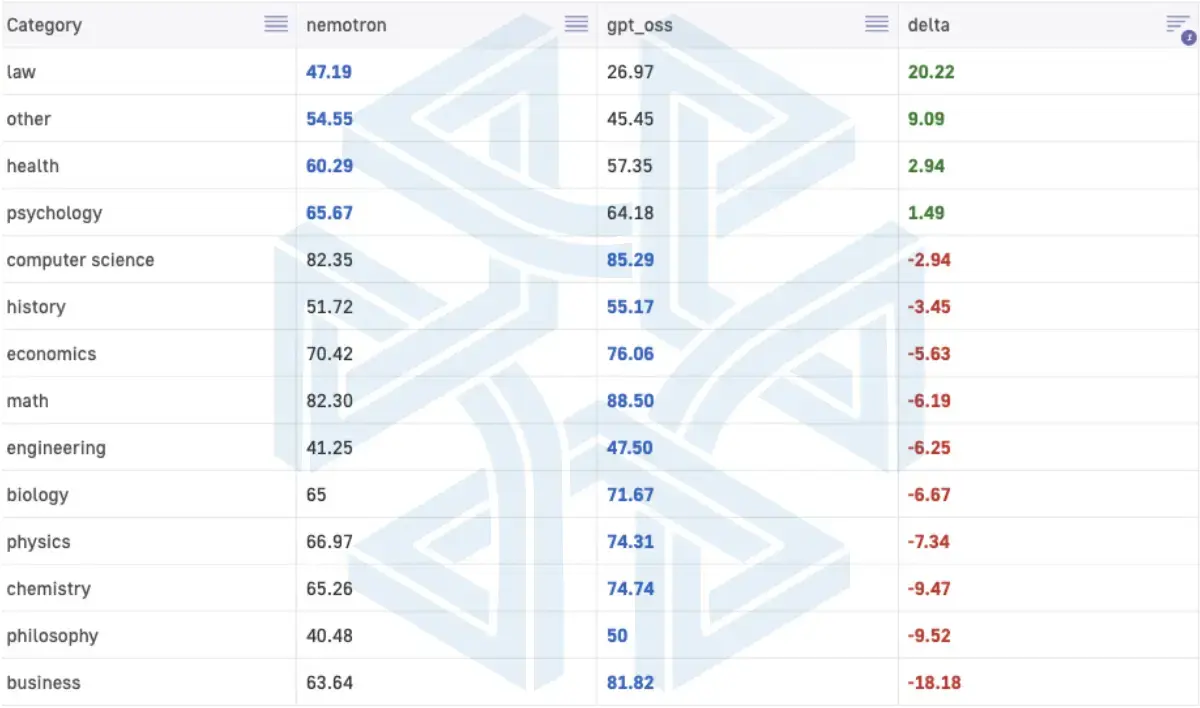
GPT-OSS scores slightly higher overall, by around 3 points, but the breakdown across subjects is mixed and depends on the domain.
GPT-OSS performs better in math, business, and physics, while Nemotron performs better in law, health, and general knowledge, and Nemotron is also more consistent in following the required answer format, which matters when you need structured outputs inside systems like MPP BI.
What this means for our work in MPP BI
We use these models inside MPP BI, we cannot assume strong performance just because a model performs well in English benchmarks. We still need to validate behavior per language and per workflow, especially in analytical systems where correctness and structure matter more than general language ability.
A Week Inside MPP BI: What We Saw
After the benchmarks, we moved to real testing inside MPP BI, because this is where model behavior actually matters.
Where the model works best
The model works best with structured data like economics, medicine, and social science, where the input is clear and the output needs to follow a fixed format.
Our MPP BI tool builds data models, creates visualizations, and runs multi-step analysis workflows. These workflows take raw data and transform it into final results through several steps. Inside these flows, the model follows instructions well and stays reliable. It completes the full process without breaking the logic or losing track of the task.
How it behaves in real use
In real usage, we noticed a consistent pattern. The model doesn’t jump to answers quickly. It spends more time checking and rechecking before it responds.
For example, when it builds a dashlet, it may first validate one aggregation, then adjust it, then check another dimension, and repeat this cycle a few times before producing the final result. The output is correct, but the process takes more steps than expected.
We also saw this when working with data sources. If we point it to a specific table, it doesn’t always stop there. It may also inspect related tables or nearby objects before acting. This sometimes helps catch missing context, but it can also slow down simple tasks.
Overall behavior
So the pattern is consistent. The model is careful, sometimes even too careful. On creativity, it is stable but not very exploratory. It works well when the task is clearly defined, like building a view or calculating a metric. But when we ask for open-ended exploration, like “show something interesting in this dataset”, it is less likely to come up with new directions.
Context handling
Context handling inside MPP BI was strong in practice. We worked with long sessions up to 256K tokens, and we didn’t see instability in real workflows. This matches what we observed in the benchmarks.
Inference speed inside MPP BI
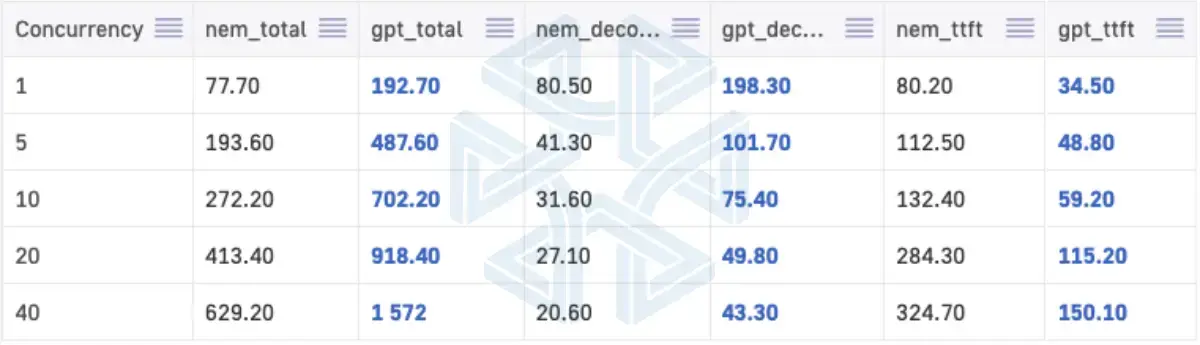
Speed became an important factor when we moved from testing to real usage inside MPP BI. We ran both models on a single RTX PRO 6000 using 2K input and 2K output tokens, and tested them under different levels of concurrent users.
System Responsiveness
At low load, both models feel responsive. Time to first token stays under 200ms, so the system reacts quickly at the start of each request.
Throughput Difference
The difference appears during generations. GPT-OSS is consistently faster. It delivers about 2.2x to 2.5x higher throughput than Nemotron depending on load. In practice, this means GPT-OSS finishes full agentic workflows faster.
For example, in a typical MPP BI flow where the model queries a dataset, checks the schema, and builds a result step by step, the full process takes about 20 seconds with GPT-OSS and around 40 seconds with Nemotron under moderate load.
This difference is clearly visible in real usage, not just in numbers.
Impact under load
At higher concurrency, it becomes even more important because it directly affects how many users one GPU can handle at the same time.
Context vs speed behavior
We also saw a pattern in behavior. When context becomes very large, GPT-OSS starts to lose stability, while Nemotron stays consistent. So the choice is not only about speed. It depends on the type of workload. Smaller and fast workflows favor GPT-OSS, while large context analytical workflows favor Nemotron.
Conclusion: What this means for MPP BI
Our team at MPP Insights see strong potential in Nemotron 3 Super, especially for analytical workflows inside MPP BI. But based on our testing, we are not switching to it for all production use cases, and the main reason is speed.
- On a single RTX PRO 6000, which is our baseline setup, GPT-OSS-120B is about 2x faster. In real MPP BI workflows, this difference is visible. Queries complete faster, and more users can be supported on the same hardware.
- For multilingual use, the improvement was limited. On Armenian and Georgian, both models performed at a similar level, and the difference was small. This means multilingual performance alone is not enough to justify slower speed in production.
- Where Nemotron clearly stands out is context handling. It stays stable even when the context becomes very large, up to 200K tokens and beyond. In MPP BI, this matters because analytical workflows often include large schemas, long queries, and multiple steps of reasoning.
- Single GPU setup also makes things more practical in real use. In MPP BI, it is easier for us to test, deploy, and iterate without complex infrastructure. It also keeps costs more predictable, which matters for real client setups. At the same time, one GPU is still a limit, especially as the number of users grows, so model efficiency becomes just as important as model quality.
When Nemotron makes sense in MPP BI
- when you need long context, around 64K to 256K tokens
- when the workflow involves complex analytical reasoning
- when you are testing new ideas or building agent-based flows
- when speed is not the main concern
When GPT-OSS is a better fit
- when you have many concurrent users
- when speed and response time matter more
- when context size stays relatively small
- when you need higher throughput on the same hardware

